

Digital transformation using our Kubernetes platform on behalf of a german logistic transport customer.
Kubernetes has become the de facto standard for container orchestration and management(1). However, as Kubernetes environments scale up in size and complexity, they can become increasingly difficult to operate and maintain. AI and machine learning can help manage the complexity and improve efficiency in Kubernetes.
The Complexity Challenge in Kubernetes
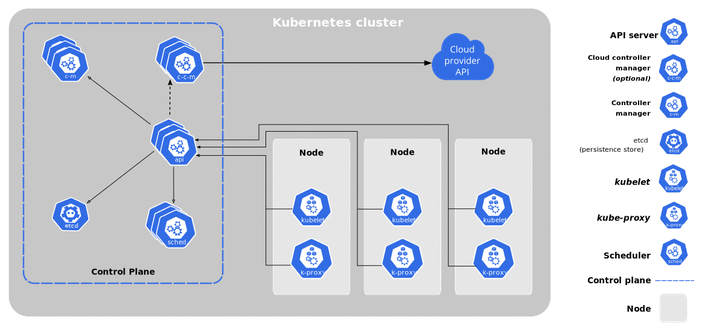
Figure 1 shows the Kubernetes components. Source (1)
A typical Kubernetes environment consists of multiple clusters with hundreds of nodes and thousands of pods running a diverse mix of workloads (See Figure 3). As engineers deploy more applications to Kubernetes, the infrastructure grows in size and intricacy. This leads to several pain points:
- The amount of configuration: Kubernetes requires a lot of configuration. The amount of configuration: Kubernetes requires extensive configuration across multiple components. There are settings at the API server, controller manager, kubelets, proxies, schedulers and more that need careful tuning for optimal functioning. The complexity stems from the need to coordinate all these distributed moving parts.
- The diversity of use cases: Kubernetes gets deployed for a wide variety of workloads from microservices to machine learning to databases. The resource requirements and configuration for these applications can vary tremendously. Each use case needs specialized configuration to ensure smooth functioning.
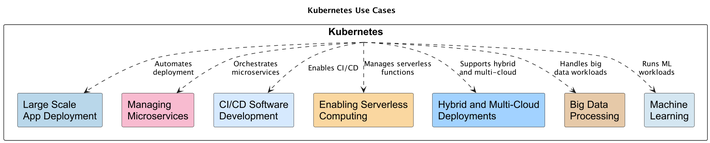
Figure 2 shows the Kubernetes use cases.
- Configuration drift and deployment errors: The highly dynamic nature of Kubernetes environments leads to configuration inconsistencies across clusters and nodes over time. This drift along with accidental misconfigurations during deployment results in subtle issues that are hard to detect.
- Operating Kubernetes at Scale: (Production Case) Managing large, complex Kubernetes environments, as shown in picture 3, presents challenges like scaling, resource management, infrastructure services, and overall observability that require robust tools and automation.
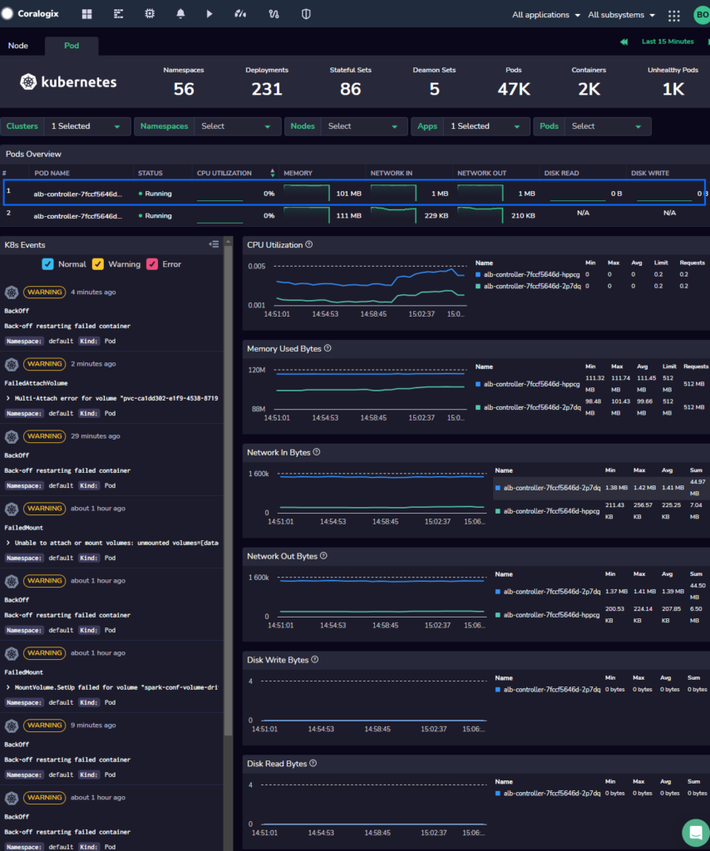
Figure 3 shows a K8s cluster at a large scale. Source (2)
- Scale: Operating large clusters with many nodes, pods and containers requires robust monitoring, management and automation tools to handle the workload efficiently.
- Pod Density: High container-to-pod ratios can complicate debugging, scaling and management. Evaluate if pod designs follow best practices.
- Unhealthy Components: A high number of unhealthy pods, containers or other components indicates underlying issues that need investigation and resolution.
- Resource Management: Careful resource management is essential in large clusters to prevent overprovisioning or underprovisioning, which can cause performance problems.
- Stateful Workloads: With many stateful workloads, the storage solution needs high performance, reliability and backup capabilities.
- Infrastructure Services: Ensure infrastructure services like DaemonSets are required on all nodes, as they consume resources on every node.
- Observability: Comprehensive observability is critical for identifying issues and monitoring health in complex environments.
- Security: More attack surfaces are exposed in large, complex environments. Security policies, controls and tools are vital.
- Automation: Automating deployments, scaling, and management tasks is necessary for operational efficiency.
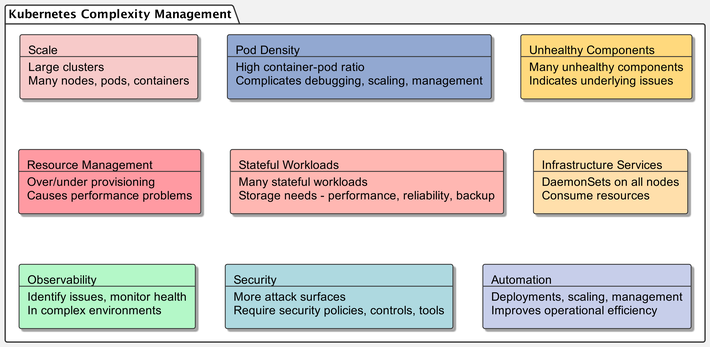
Figure 4 summarizes the challenges of Kubernetes cluster management.
In summary, the complexity arises from Kubernetes' vast configuration surface area spanning multiple components, integration with diverse applications, and tendency for configurations to drift at scale. This makes Kubernetes environments intrinsically complex necessitating solutions like AI/ML for simplified management.
AI/ML in Kubernetes Optimization
AI can provide several advantages in optimizing and managing complex Kubernetes (K8s) environments. Here's how AI could help in improving the setup you provided:
Predictive Resource Allocation
AI can analyze historical usage patterns of workloads to predict future resource requirements. This can help in optimally allocating resources, reducing wastage, and ensuring applications have the resources they need when they need them (3).
Anomaly Detection
By analyzing metrics and logs, AI can identify unusual patterns or anomalies, such as a sudden spike in resource usage or unexpected downtimes, and alert administrators (4).
Root Cause Analysis
Given the 1,000 unhealthy pods in the setup, AI can assist in rapidly pinpointing commonalities between them or patterns leading up to their failure, thus helping in root cause analysis.
Auto-Scaling Optimization
While Kubernetes has built-in auto-scaling, AI can enhance decision-making by considering more factors and patterns. For instance, if a sales application always sees a spike in usage at the end of the month, AI can proactively scale it up in anticipation. (2,3,4)
Cost Optimization
For cloud-hosted Kubernetes clusters, AI can provide recommendations on right-sizing resources, selecting optimal instance types, or even suggesting when to use spot instances to save costs. (3)
Security Enhancements
AI can detect unusual access patterns or potential security breaches by analyzing network traffic and access logs, thus enhancing the security posture of the cluster. (5,6)
Optimal Container-to-Pod Design
Given the high container-to-pod ratio in the setup, AI can suggest optimal groupings based on inter-container communication patterns, dependencies, and resource usage.
Recommendation Systems
AI can suggest best practices, configurations, or architectural changes based on the current setup, benchmarking against known best patterns and practices in the industry. (5)
Automated Testing & Quality Assurance
AI can assist in implementing automated testing strategies, identifying common points of failure, and suggesting improvements. (6,7)
Proactive Maintenance
AI can predict potential failures based on historical data. For example, if a node or a set of pods frequently goes down under specific conditions, AI can alert administrators proactively or even take preventive measures. (7)
Workload Placement
By analyzing workload characteristics and node capacities, AI can recommend where workloads should be placed for optimal performance and resilience. (2,3,6,7)
Conclusion
In conclusion, as Kubernetes environments scale in size and complexity, they present growing operational challenges like extensive configuration needs, diverse workloads, configuration drift, and issues with observability and automation.
As summarized in the table below, AI can provide optimizations across a breadth of Kubernetes resources and tasks, from predicting resource needs to automating scaling and enhancing security. The techniques discussed, such as predictive analysis, anomaly detection, and recommendation systems, demonstrate the power of AI to drive efficiency and simplify operations.
| Symbol | Resource | Quantity | How AI Can Optimize |
| N | Namespaces | 56 | Analyze workload boundaries for better resource allocation and predict future namespace requirements. |
| S | StatefulSets | 231 | Predict storage growth and optimize storage provisioning based on historical data. |
| d | DaemonSets | 5 | Monitor node-wide resources to optimize DaemonSet distribution and scaling. |
| p | Pods | 2,000 | Analyze pod performance metrics, optimize container allocation, and enhance auto-scaling decisions. |
| c | Containers | 47,000 | Monitor container health, predict failures, and optimize image build processes. |
| u | Unhealthy Pods | 1,000 | Use pattern recognition to identify root causes and suggest corrective measures. |
Legend:
Blue: Daily business tasks
Blank: Architecture Design
Orange: Architecture planning tasks
Red: Production monitoring tasks
Figure 5 illustrates how AI can help optimize Kubernetes cluster management by utilizing metrics from Figure 3 related to common DevOps tasks like monitoring, autoscaling, and predictive analysis.
If you're wondering how to get started, the table below provides actionable recommendations. Good first steps include instrumenting your environment to collect the data AI models need, running small pilots to prove value, and integrating compatible solutions into your tech stack. Tracking measurable outcomes is also advised to showcase AI impact over time.
Ultimately, developing in-house machine learning skills and processes is key to sustain long-term success. With the insights and advice summarized here, you're now equipped to commence your organization's AI-powered Kubernetes journey. The next step is to formulate a vision and roadmap for adoption. Thank you for reading, and I hope you found this guide useful. Wishing you the very best as you leverage AI to automate away Kubernetes headaches and unburden developers.
| Getting Started with AI Ops | |
|---|---|
| Instrument environments early to collect metrics, logs and traces required for AI/ML algorithms. | |
| Start with targeted pilots for specific use cases like AIOps, automated scaling etc. before expanding. | |
| Evaluate AI/ML solutions compatible with your tech stack that provide easy integration and pre-built models. | |
| Frame objectives and metrics to measure the impact of AI adoption. Track improvements over time. | |
| Develop in-house machine learning expertise and workflows to sustain long-term AI operations. |
References
- 16 Best Container Orchestration Tools And Services In 2023 (devopscube.com)
- Kubernetes Authors. (n.d.). Components of Kubernetes. Kubernetes. https://kubernetes.io/docs/concepts/overview/components/
-
Turin, G., Borgarelli, A., Donetti, S., Damiani, F., Johnsen, E.B., & Tapia Tarifa, S.L. (2023). Predicting resource consumption of Kubernetes container systems using resource models. The Journal of Systems & Software, 203, 111750. https://doi.org/10.1016/j.jss.2023.111750
-
Almaraz-Rivera, J. G. (2023). An anomaly-based detection system for monitoring Kubernetes infrastructures. IEEE Latin America Transactions, 21(3), 457-465.
-
Gulenko, A., Kao, O., & Schmidt, F. (2020). Anomaly detection and levels of automation for AI-supported system administration. In F. Xhafa, S. Caballe, R. Abraham, T. Daradoumis, & A. Juan Perez (Eds.), Information management and big data: 6th international conference, SIMBig 2019, Lima, Peru, August 21–23, 2019, proceedings (pp. 1-7). Springer International Publishing.
-
Kaur, R., Gabrijelčič, D., Klobučar, T., & Artificial intelligence for cybersecurity: Literature review and future research directions. Information Fusion, 97, 101804. https://doi.org/10.1016/j.inffus.2023.101804
-
Borg, M., 2022, January. Agility in software 2.0–Notebook interfaces and MLOps with buttresses and rebars. In International Conference on Lean and Agile Software Development (pp. 3-16). Cham: Springer International Publishing.