

Microsoft's AI supercomputer is located in Quincy, Washington, USA. Photo Credit: Microsoft
ChatGPT's meteoric rise in popularity has sparked renewed excitement and debate around artificial intelligence. Powering chatbots like these are enormous AI models termed "large language models" (LLMs), which can contain upwards of trillions of parameters. Training and running models of this unprecedented size requires an equally unprecedented computing infrastructure.
In 2020, Microsoft quietly built one of the world's most powerful supercomputers to host OpenAI's models. Shrouded in secrecy, this system demonstrated the company's prowess in designing specialized hardware and software for artificial intelligence workloads.

Microsoft Chief Technology Officer Kevin Scott, PhD, showes the key features of artificial intelligence capabilities at Microsoft. Photo credit: Microsoft
Recently, Microsoft's Azure CTO Mark Russinovich peeled back the curtain on the AI supercomputer powering today's most advanced LLMs. In this behind-the-scenes look, we'll explore how Microsoft engineered this cutting-edge infrastructure to make the seemingly impossible possible when it comes to AI.
Follow along as we delve into the immense scale, optimized architecture, and advanced capabilities that enable this neural network behemoth to deliver history-making AI to millions worldwide. The advancements coming out of secretive labs like these promise to fundamentally reshape technology as we know it in the coming months.
The Challenge of Training Massive AI Models
Training massive artificial intelligence models like ChatGPT requires an immense, specialized infrastructure. At the core are facilities packed with racks upon racks of GPU-powered servers, blinking away as they process astonishing volumes of data. ChatGPT's training involved ingesting billions of webpages, books, and more - a corpus so large it would take a single person millions of years to read through.
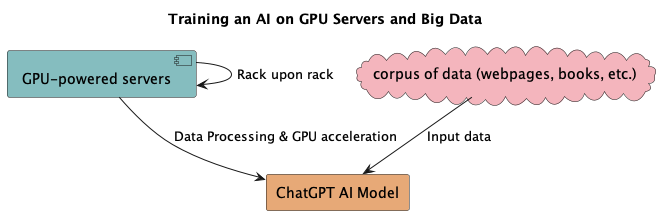
To handle such a data deluge, these facilities are equipped with cutting-edge hardware designed specifically for parallel processing and high-throughput computations. Teams of engineers have meticulously developed optimized software that can efficiently coordinate the training across hundreds or thousands of GPUs simultaneously.
But operating at this scale comes with immense challenges. With so many components running non-stop, hardware failures are a constant threat. Servers crash unexpectedly. Network links falter. Bugs in the code can grind progress to a halt. The infrastructure has safeguards in place, with failover mechanisms that allow training to resume quickly. There is redundancy built into the rigs - if one GPU fails, another seamlessly takes over.

The goal is to maximize GPU utilization round-the-clock, extracting every last bit of processing power from the expensive hardware. Software manages partitioning and scheduling the work to fully saturate the resources. Despite precautions, interrupted training sessions still happen. Significant progress could be lost. Checkpointing systems help here too, periodically saving the model state so training can roll back to the most recent save point instead of starting from scratch.
Training a model like ChatGPT demands an intricate infrastructure specifically tailored for the monumental compute demands of artificial intelligence. It pushes hardware, software, and humans to their limits in pursuit of a machine that can perceive, learn, and communicate.
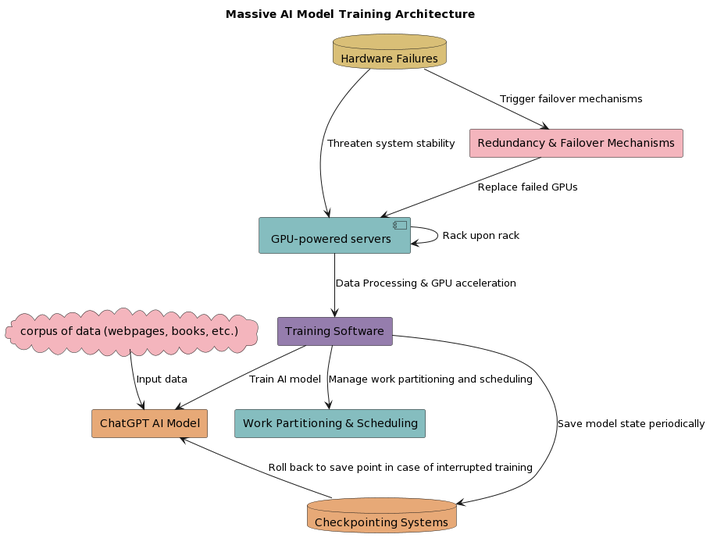
Decoding the Architecture of Azure AI Supercomputer
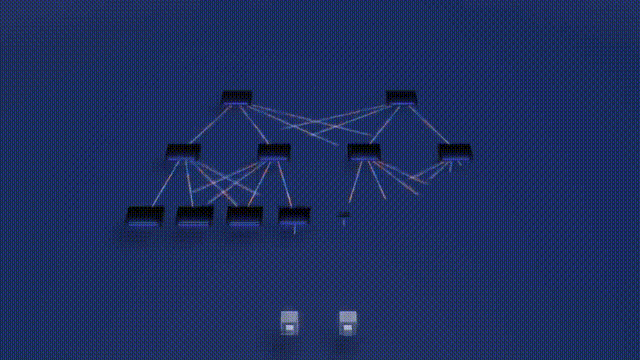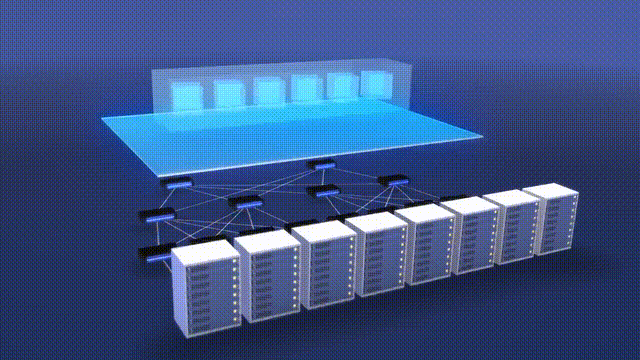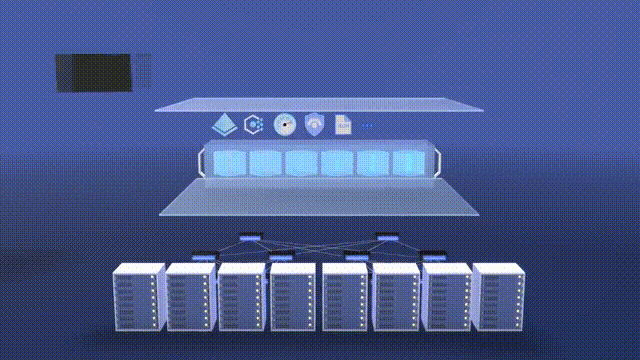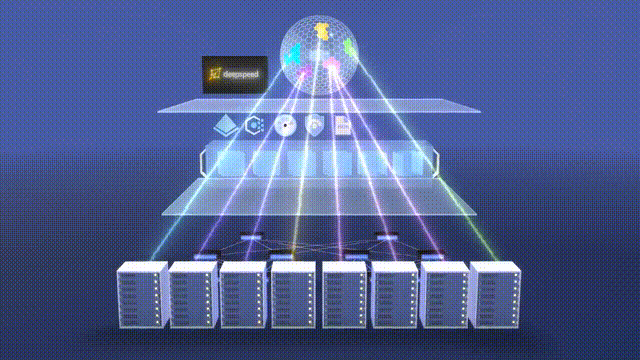
Animation of the Supercomputer Facility Used for AI Training Model Source: Mark Russinovich at Microsoft (2023)
The supercomputer for AI was the result of a collaborative effort between Microsoft engineering, Microsoft Research, OpenAI, and NVIDIA. The idea was to provide IT infrastructure - software, hardware, and know-how - to support training and inference of large language models (LLMs) with hundreds of billions of parameters. This includes clustering GPUs with high-bandwidth networking for efficient parallelized training. The AI supercomputer built for OpenAI in 2020 had over AMD 285,000 CPU cores and 10,000 GPUs connected with InfiniBand networking. This was the 5th largest supercomputer in the world at the time.

Central processing units (CPUs) are the primary processors in any computing system. Having 285,000 CPU cores indicates a vast amount of processing power that can perform a colossal number of computations simultaneously. This is particularly useful for the many smaller tasks involved in machine learning applications, such as data preprocessing.

NVIDIA V100 Tenso Core GPU are especially adept at performing the sort of parallel computations required for machine learning and particularly deep learning, which involves processing a lot of matrix and vector operations. 10,000 of these GPUs implies a highly potent computational force capable of significantly reducing the time taken to train large language models.

Server with 8 NVIDIA V100 GPUs designed for machine and deep learning training.
Photo credit: Microsoft.

A close-up photo highlighting the InfiniBand ports and cables on the back of a server in an Azure data center. Photo credit: Microsoft Azure, 2023. InfiniBand is a high-performance, low-latency networking technology that enables fast data transfer between components, such as CPUs and GPUs, in a computing system. This technology is vital for efficiently coordinating the vast number of CPUs and GPUs in the supercomputer, especially when the model is distributed across multiple GPUs for parallel computation (data parallelism).
Running AI Workloads at Scale
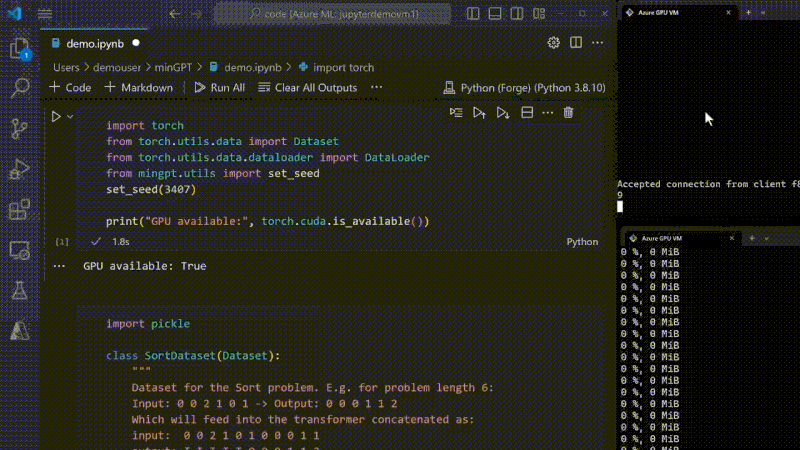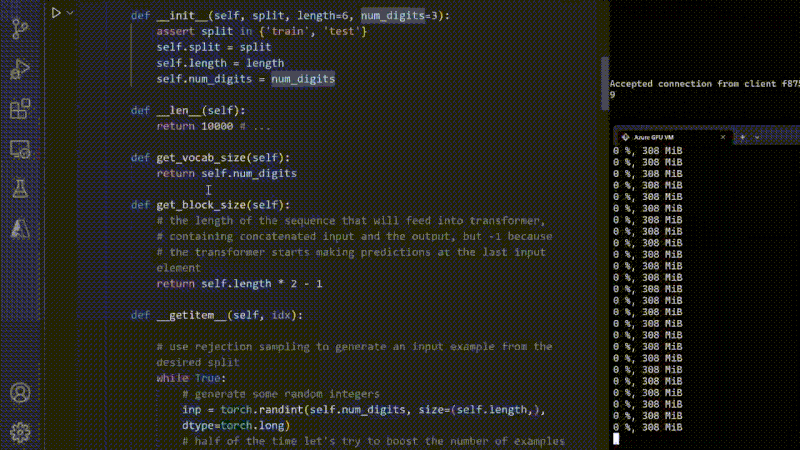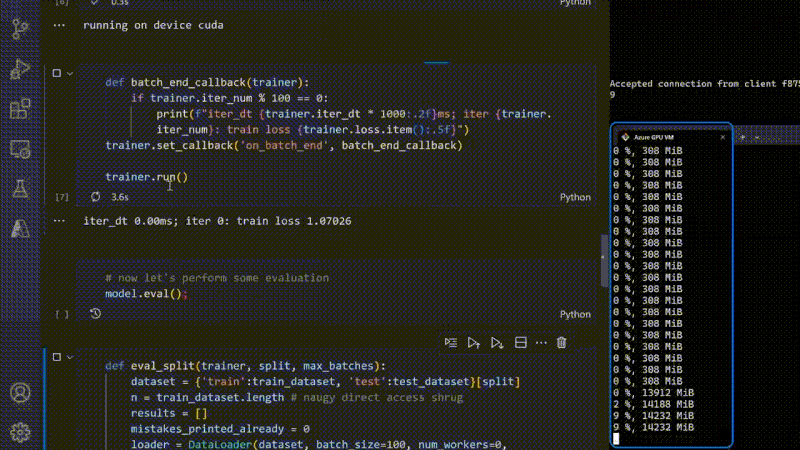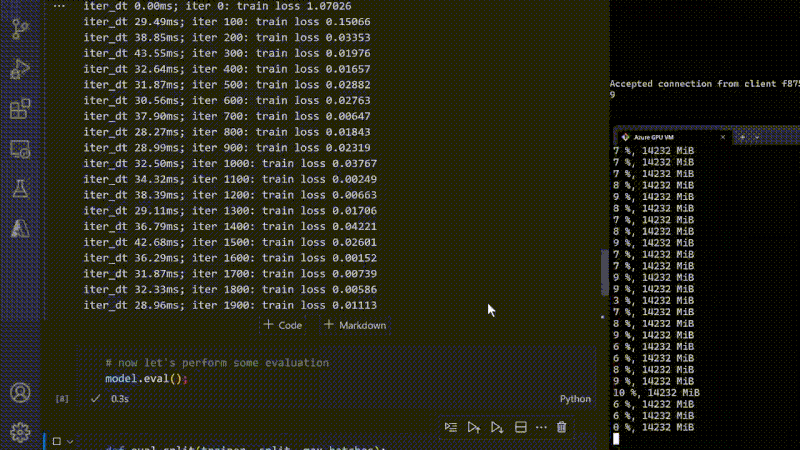
Demonstration Training of a Model using MinGPT and Python Forge to demonstrate the capabilities of GPU, checking the memory consumption. - Mark Russinovich at Microsoft (2023)
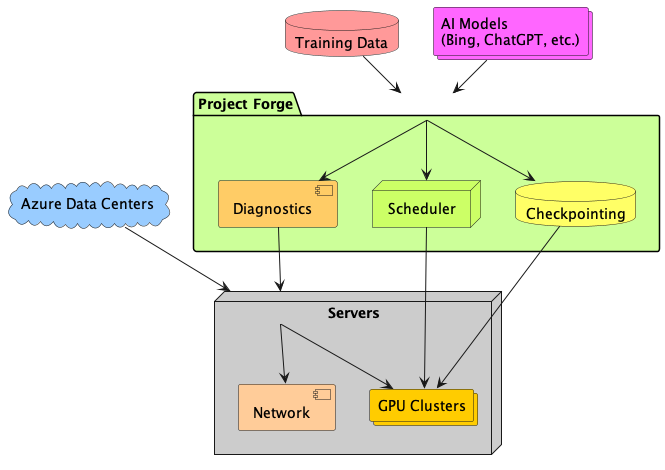
At Microsoft's sprawling data centers, banks of servers hum away day and night training some of the world's largest AI models. This non-stop workload is made possible by Project Forge, a robust infrastructure tailored for relentless artificial intelligence workloads.
Project Forge allows models like ChatGPT to be trained continuously for months without interruption. The system features incremental checkpointing, automatically saving progress at frequent intervals so that any failures won't result in starting over from scratch.
A global scheduler intelligently parcels out pieces of the workload across available compute resources, balancing utilization for optimum efficiency. Diagnostic systems provide rapid detection and recovery from the inevitable hardware issues that crop up at this scale.
For now, Project Forge is used internally at Microsoft to power expansive AI models that drive products like Bing. But soon this infrastructure will be offered to Azure cloud customers, enabling broader access to train cutting-edge AI without the daunting task of assembling such an environment themselves.
Project Forge represents the massive compute capabilities required to make artificial intelligence usable in real world applications. By offering it as a service, the power to build the next generation of AI will be available at your fingertips.
Conclusion
Microsoft built specialized AI supercomputers to push the frontiers of artificial intelligence. Packed with advanced GPUs and optimized hardware and software, these systems empowered new AI capabilities like models with over 100 billion parameters approaching human brain complexity. By leveraging its technical expertise and cloud infrastructure, Microsoft invested heavily to tailor every component for AI's demanding workloads. This enabled breakthrough benchmarks in natural language processing, as evidenced by ChatGPT. While just the beginning, Microsoft continued stretching boundaries in AI supercomputing to drive profound innovations. As they democratized access to their optimized cloud platform, more organizations could deploy leading-edge AI. Though these systems seemed basic in years, for now they represented the cutting-edge in integrating AI deeper into our lives. Where Microsoft's grand AI experiment went next remained unseen, but it shaped the future in ways we could only start to imagine.
References
- Russinovich, M., & Chapman, J. (2023, May 24). What runs ChatGPT? Inside Microsoft's AI supercomputer. [Video]. YouTube. https://www.youtube.com/watch?v=Rk3nTUfRZmo
- Scott Kevin (2020) Microsoft Build 2020: CTO Kevin Scott on the future of technology.[Video]. Youtube. https://www.youtube.com/watch?v=eNhYTLWQFeg