

Have you heard of the wildly popular online game GeoGuessr, where players try to pinpoint the location of randomly generated Google Street View images? Well, researchers from Stanford have developed an artificial intelligence system called PIGEON that can do just that - and it consistently beats even the top human players!.
In a new scientific publication (1), the researchers detail how they created PIGEON, which leverages state-of-the-art deep learning techniques to achieve over 90% country-level accuracy and 40% street-level accuracy on guessing the location of Street View panoramas.
How does PIGEON work it s geolocation magic?
The researchers came up with a novel geocell creation algorithm (see below) that splits the globe into over 2,000 geographic cells based on the distribution of the training data. This converts latitude/longitude regression into a more feasible classification task.

The PIGEON model utilizes the sophisticated Semantic Geocell Division Algorithm to elegantly partition expansive geocells into smaller, semantically meaningful units. This algorithm operates on the following inputs:
- 'g': The initial geocell boundaries.
- 'x': Training data points.
- 'p': Parameters for the OPTICS clustering algorithm.
- 'MINSIZE': The minimum number of points required within a cell.
The algorithm iteratively executes the following steps:
1. Employ OPTICS clustering, leveraging parameters 'pj', to cluster the points 'xi' within each initial geocell 'gi'.
2. Identify the largest cluster, 'cmax', within each cell.
3. If both 'cmax' and the remaining points 'xi \ xi,k' contain more than 'MINSIZE' points, construct a new cell, 'gnew', that encompasses 'cmax' using Voronoi tessellation over the points 'xi,k'.
4. Subtract 'gnew' from the original cell 'gi'.
5. Assign the points 'xi' to the new cells 'i' and 'new'.
6. Repeat the process with new parameter settings for OPTICS given by 'p' until all settings in 'p' have been utilized.
This algorithm facilitates the division of large cells into smaller ones in a data-driven manner, guided by the clustering of points. The utilization of Voronoi tessellation ensures that the resulting cells possess semantic coherence. Consequently, the algorithm yields geocells that exhibit improved size balance and preserve geographical semantics.
PIGEON also employs a pre-trained vision transformer called CLIP that was trained on millions of image-text pairs. This gave PIGEON a big boost over convolutional neural networks. The researchers took it a step further with "StreetCLIP", fine-tuning CLIP on Street View images and generated location captions. But before, we conitnue, need a break to explanin some key concepts:
What is CLIP?
CLIP represents a shift in natural language processing from models that understand just text or just images to those that understand both together. The Contrastive Language-Image Pretraining model developed by OpenAI trains two transformers to process images and text independently while maximizing similarity between matching pairs and minimizing it for non-matching pairs. This enables CLIP to rank images based on text queries and vice versa through zero-shot learning, without requiring task-specific fine-tuning (1). The joint image-text understanding allows CLIP to generalize to new tasks in a zero-shot manner based on what it learned during pretraining. This sets it apart from prior models focused solely on either images or text in isolation rather than in conjunction.
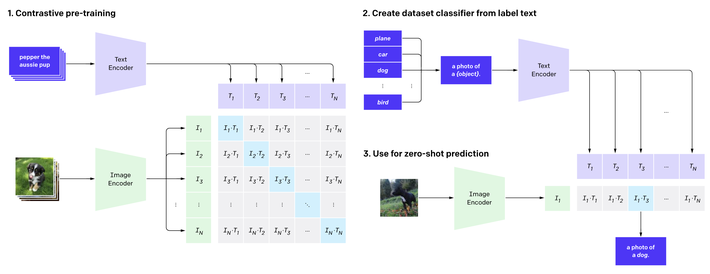
The key innovation of CLIP is pretraining an image encoder and text encoder to predict matching image-text pairs in its dataset. This enables zero-shot classification by converting class labels into captions and predicting the class whose caption CLIP determines best matches a given image. Rather than requiring task-specific datasets and training, CLIP can classify images simply based on the knowledge of the visual world learned during its initial pretraining phase.
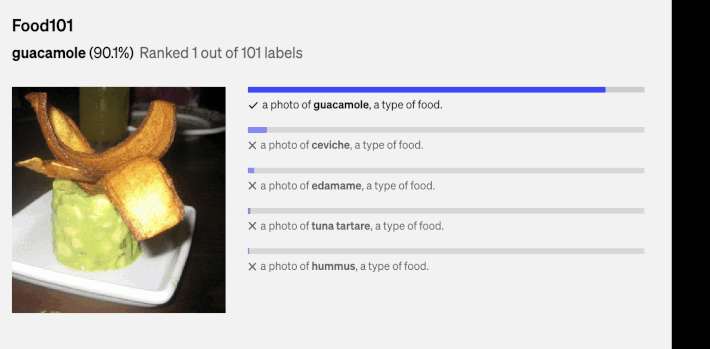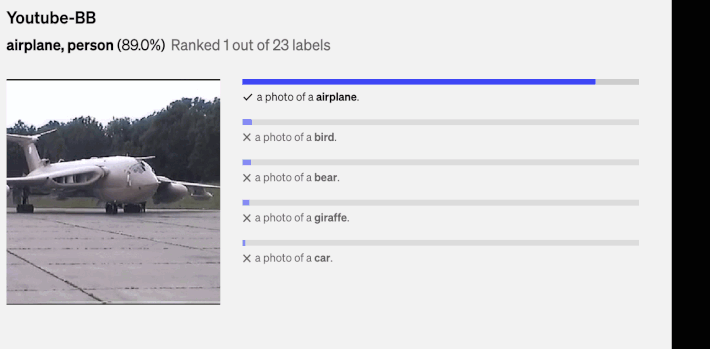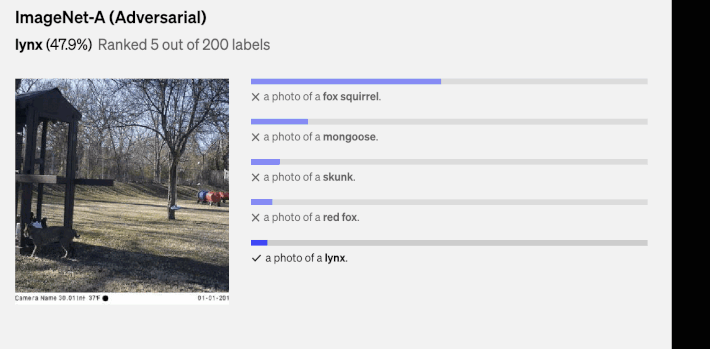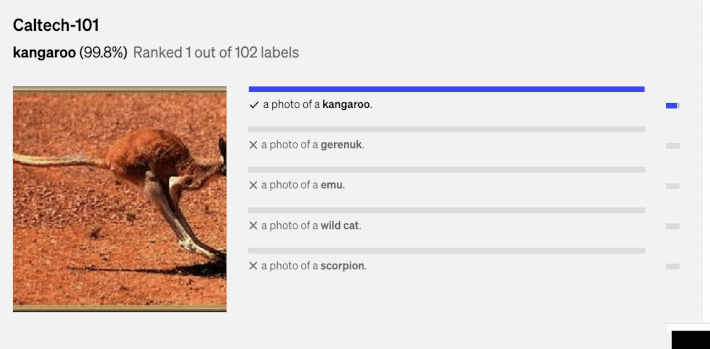
Above, there are a couple of the random predictions from zero-shot CLIP classifiers on diverse dataset examples done by (1).
What is StreeCLIP?
StreetCLIP is a robust foundation model for open-domain image geolocalization and other geographic and climate-related tasks (2)

StreetCLIP was pre-trained using artificial image captions. These captions describe the location of each training image using natural language. Specifically, the captions state the city, region, and country where each training image was taken. This teaches StreetCLIP to understand location information described in natural language. See the example below:
A Street View photo close to the town of {city} in the region of {region} in {country}.
This allows StreetCLIP to synthesize a generalized zero-shot learner tailored to geolocalization for every training batch. In this manner, StreetCLIP meta-learns how to effectively leverage zero-shot learning within the geographic domain. (2)
So in essence, StreetCLIP extends CLIP by additional representation learning on geographic data, creating vision-language encoders specialized for geo-localization tasks.
StreetCLIP builds on top of the CLIP model which is trained using contrastive learning. The core components are:
- An image encoder \(g(v)\) that encodes an image \(v\) into an embedding space \(\mathcal{V}\):
\(g: \mathcal{V} \rightarrow \mathbb{R}^{d_v}\)
- A text encoder \(f(x)\) that encodes text \(x\) into an embedding space \(\mathcal{X}\):
\(f: \mathcal{X} \rightarrow \mathbb{R}^{d_x}\)
- A contrastive loss function that brings matched image-text pairs close and pushes non-matching pairs apart in the joint embedding space:
\(\mathcal{L}_{\text{contrastive}} = \sum_{(i,j)} \mathbb{I}_{i=j} d(v_i, x_j) + (1 - \mathbb{I}_{i=j}) \max(0, \alpha - d(v_i, x_j))\)
During pretraining, backpropagation on this loss trains encoders \(g\) and \(f\) to create useful joint representations for visual and textual data. StreetCLIP further pretrains the encoders on StreetView images and synthetic captions with geographic details, continuing to learn via contrastive learning.
GZSL?
PIGEON formulates image geolocalization as a generalized zero-shot learning (GZSL) problem (1).
Let \(Y_s = \{y_s^1, ..., y_s^{N_s}\}\) be the set of seen classes during training and \(Y_u = \{y_u^1, ..., y_u^{N_u}\}\) the set of unseen classes. The goal is to learn a model \(f(x)\) that can classify inputs \(x\) into classes from both \(Y_s\) and \(Y_u\).
During training, the model only has access to a labeled dataset \(D_{tr} = \{(x_i, y_i) | y_i \in Y_s\}\).
At test time, the dataset is \(D_{ts} = \{(x_i, y_i) | y_i \in Y_s \cup Y_u\}\).
StreetCLIP approaches this by using the CLIP image encoder \(g(v)\) and generating class embeddings for \(Y_s\) and \(Y_u\) from the text encoder \(f(x)\).
For an input image \(v\), the predicted class \(\hat{y}\) is obtained by:
\(\hat{y} = \argmax_{y \in Y_s \cup Y_u} \cos(g(v), f(y))\)
Where \(\cos\) denotes cosine similarity. So the image is classified to its most similar class embedding.
This allows zero-shot generalization to unseen classes \(Y_u\) at test time.
How to Use the StreetClip?
To use StreetCLIP for image geolocalization, first go to the model page at https://huggingface.co/geolocal/StreetCLIP. Then, upload a photo (for example, a photo I took of the Westminster Cathedral) that needs to be geolocalized. We can prompt the model with captions referring to different geographic locations, such as "Northern Europe", "UK", or "Sweden", to hierarchically search for the image's origin. Finally, click the compute button to start the search and obtain the predicted geographic coordinates for the photo. The process is illustrated in the animation below.

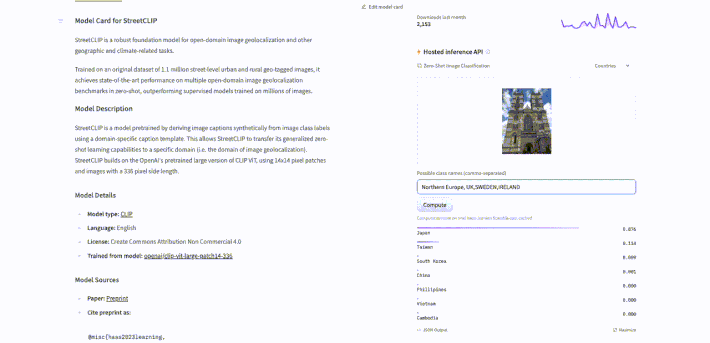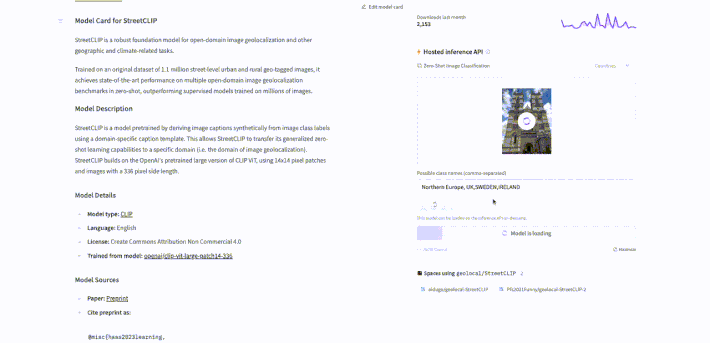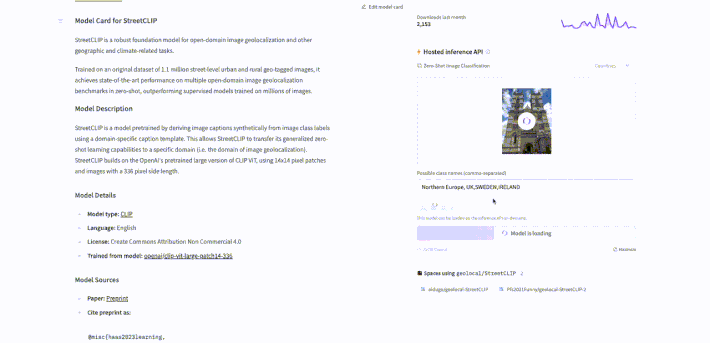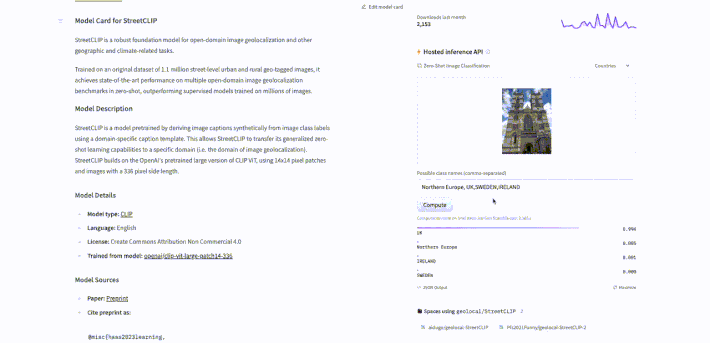


StreetClip identified the country in the photo with a 99.4% probability of being the UK! After, I tested it again with some cities and it predicted London with 100% probability. See the results below.

Conclusion
PIGEON pushes the boundaries of what is possible for planet-scale image geolocalization. It points a promising way forward for flexible models that learn visual representations tailored for geographic tasks. By combining insights from transformers, multi-task learning, metric learning, and transfer learning, PIGEON achieves remarkable results on the GeoGuessr benchmark. More broadly, it provides a foundation for further research at the exciting intersection of computer vision, geospatial data, and artificial intelligence.
References
- Radford, A., Kim, J.W., Hallacy, C. et al. (2021) Learning Transferable Visual Models From Natural Language Supervision. OpenAI. https://openai.com/research/clip.
- Haas, L., Alberti, S., & Skreta, M. (2023). Learning generalized zero-shot learners for open-domain image geolocalization [Preprint]. arXiv. https://arxiv.org/abs/2302.00275
Write a comment